Gradient Descent and its variations
Table of contents
- What is Gradient Descent (GD)?
- Blind Bear Climb the Hill
- How does the Gradient Descent Work?
- Batch Gradient Descent (BGD)
- Stochastic Gradient Descent (SGD)
What is Gradient Descent (GD)?
“A gradient measures how much the output of a function changes if you change the inputs a little bit.” — Lex Fridman (MIT)
Gradient Descent is an optimization algorithm used for minimizing the cost function in various machine learning algorithms. It is basically used for updating the parameters of the learning model.
Blind Bear Climb the Hill
I will use the chart to help you to understand what is gradient descent.
<p style="text-align: center;">
 <p>
<p>
Figure 1. A Bear Climb the Hill
You can imagine a blind bear wanting to climb to the top of a hill with the fewest steps possible. When the bear started climbing, he will take big steps which he can do as long as he is not close to the top. While the bear comes closer to the top, his steps will get smaller and smaller to avoid overshooting the top point. You can think this process is using the gradient.
In mathamatics, we can use the below figure to explain it.
<p style="text-align: center;">
 <p>
<p>
Figure 2. Gradient Descent - Top View
You can imagine the red arrows are the steps of the bear and the center of the circle is the top point. In the beginning, the gradient range is much longer than the others.
How the Gradient Descent Work ?
When we learn some machine learning models, we need to use the gradient descent method to resolve the result. Now we need to understand how it is working.
<p style="text-align: center;">
 <p>
<p>
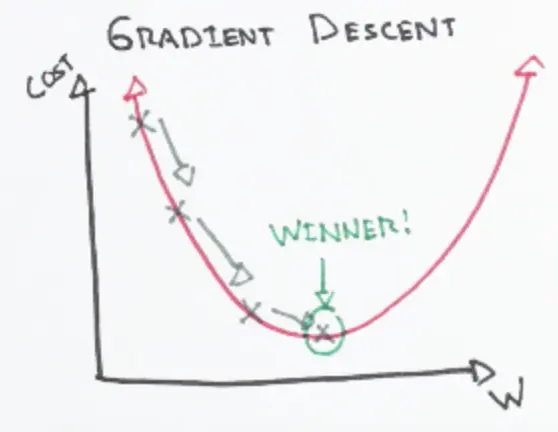
Figure 3. Gradient Descent - Front View
We hope we can get the optimized point in a short time. Therefore, we need to reduce the interactive times. The gradient descent can help us to do that.
In machine learning, we input the initial value and then get the gradient information of the function. We can move a certain distance (step size) in the gradient descent direction (negative gradient direction) and then get the next point. In this case, we find the gradient descent direction of this point, and so on, constantly approaching the minimum value.
Batch Gradient Descent (BGD)
Batch gradient descent(vanilla gradient descent) calculates the error for all data within the training dataset. After calculating all training examples, the parameter of the model gets updated. Therefore, if the size of the dataset is large, the batch gradient descent is very expensive to calculate.
Stochastic Gradient Descent (SGD)
Stochastic gradient descent (SGD) will calculate the error for each training example. Thus, SGD does not calculate all data within the training dataset. The advantage of stochastic gradient descent is faster than batch gradient descent. However, the noisy data will cause the error rate because SGD calculates each data to update the parameter.
<p style="text-align: center;">
 <p>
<p>
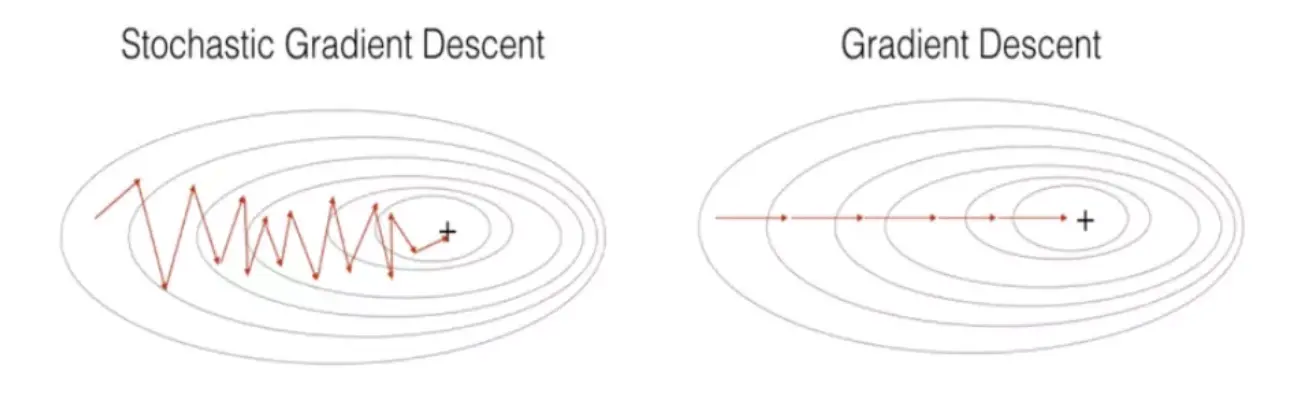
The image above explains the difference between SGD and BGD. SGD will iterate more times, but the time of each iteration is slow. Thus, SGD is faster than BGD.
Figure 4. SGD vs. GD